Data Flywheel
The Data Flywheel is a self-reinforcing loop: data improves AI performance, which enhances the user experience, leading to more usage—and thus more data. A strong flywheel can become a powerful competitive moat, giving you superior data and smarter AI that keeps users engaged. By continuously aligning with real-time user behavior, the flywheel also protects your system against drifts, i.e. the decline in AI performance as input data evolves.
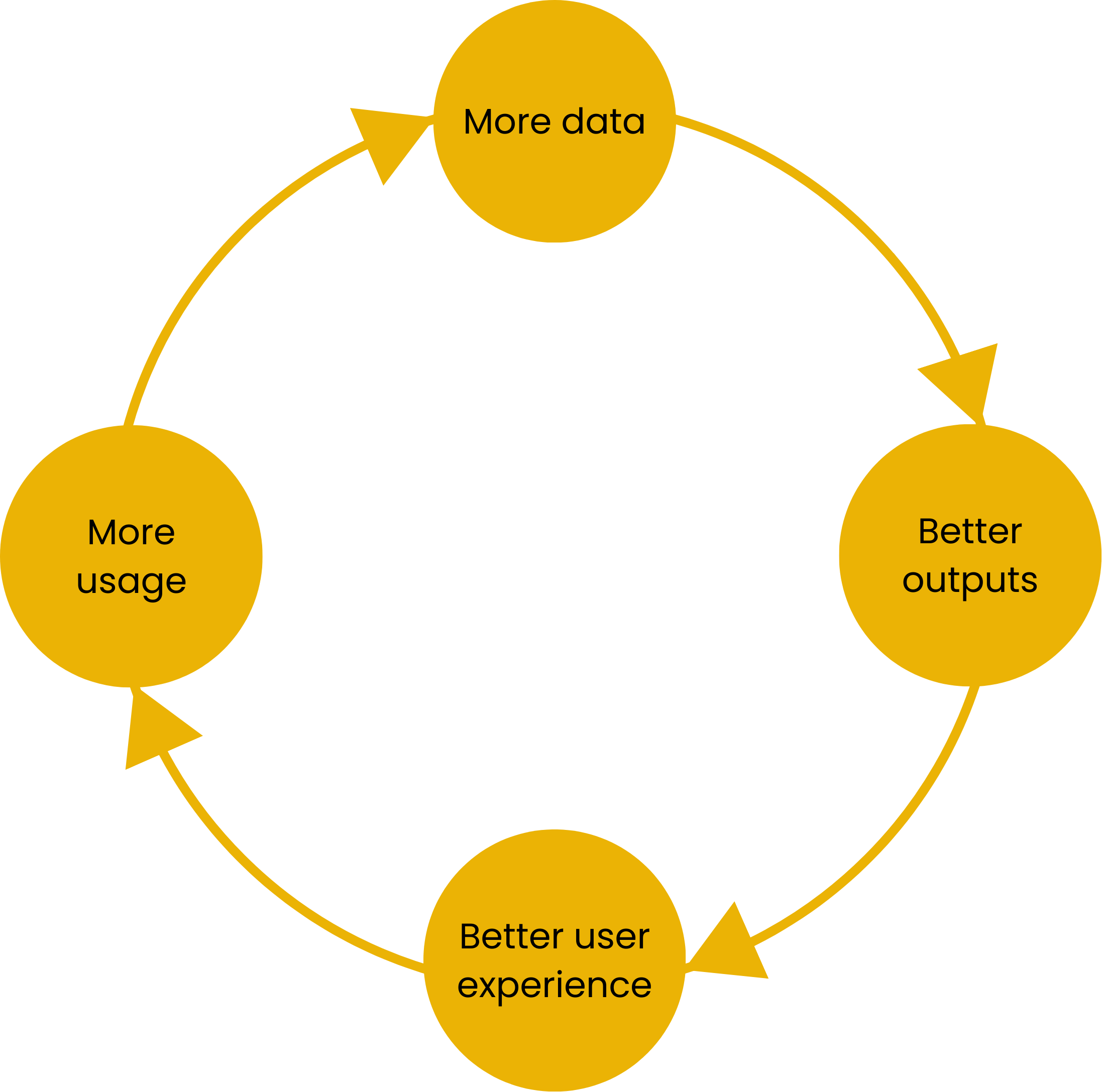
Principles
Model performance improves with high-quality, high-volume data
User interactions are a strategic data asset—not just UX signals
Every product touchpoint can become a data collection opportunity
Feedback loops must be intentional, measurable, and privacy-respecting
A functioning flywheel compounds over time and becomes a moat
Implementation steps
1Instrument user interactions
Identify and track user behaviors that reflect engagement, correction, abandonment, or trust. Focus on both implicit signals (e.g. scroll depth, hovers) and explicit feedback (e.g. ratings, thumbs up/down).
2Define data quality standards
Establish criteria for which interaction data should be included in training (e.g., clean, relevant, diverse, representative). Ensure privacy and compliance are built in from the start.
3Close the feedback loop
Create pipelines that push curated interaction data back into model training or fine-tuning. This may involve human labeling, confidence-based routing, or automation depending on the context.
4Monitor flywheel health
Track metrics like feedback volume, model improvement velocity, engagement uplift, and user retention.
5Overcome plateaus
Eventually, your flywheel will slow down. Use strategies to regain momentum, like adding new types of interactions to enrich the feedback, or removing friction from your feedback mechanisms.
6Scale and defend the loop
As your flywheel matures, expand data sources and use differentiated data as a strategic moat against competitors.
Anti-patterns
Data hoarding: Collecting large volumes of data without a clear plan to use it effectively in model training.
Static data strategy: Treating data as a one-time asset instead of an evolving, renewable input.
Privacy negligence: Collecting user data without transparency, consent, or safeguards, risking trust and compliance.
Resources
AI User Experience (book chapter from The Art of AI Product Development) on user feedback collection